qr_multiply multiplies a vector/(batched) matrix c on the right/left by an orthogonal matrix Q derived from QR decomposition, and also returns the upper triangular matrix R as a second argument. Importantly, it never materialises Q and instead uses scipy.linalg.qr’s "raw” householder product representation and feeds this into LAPACK’s ormqr.
The way the reference LAPACK implementation for ormqr works is to apply Q using blocked householder products (larfb) I - V T V^T where T is an upper triangular matrix. These upper triangular matrices T need to be reconstructed from the raw decomposition using larft. However, this is wasteful as geqrf actually computes these T matrices during the decomposition and throws them away.
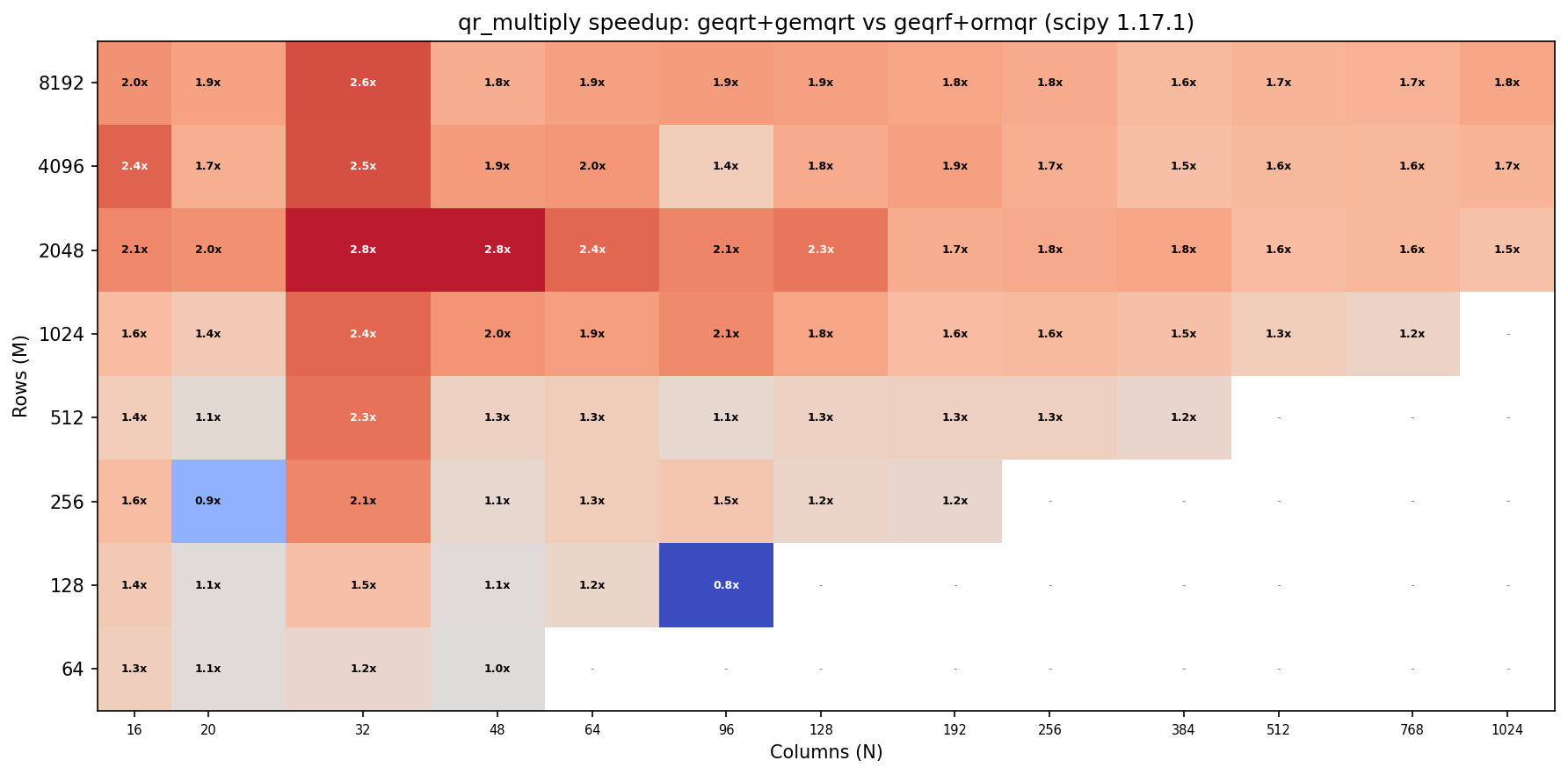
LAPACK instead exposes geqrt which computes the factorisation and returns the (nb x k) T blocks alongside and provides gemqrt to use . These were already exposed in scipy.linalg.lapack 7 years ago as part of the 1.4.0 milestone in #10345 addressing issue #10323. Benchmarking these (with block sizenb=min(k,64) on the 1.17.1 release (to eliminate noise from all the C++ implementation going on in main that can affect performance) shows that they can provide speedups of up to 2.8x on MacOS Accelerate (I ran a few tests on a small cloud CPU with OpenBLAS and saw a similar speed up there too).
I considered using LAPACK dgeqr/dgemqr (which selectively dispatches to dlatsqr/dlamtsqr in the very tall/very skinny case and otherwise falls back to dgeqrt/dgemqrt). However, on MacOS Accelerate this performs catastrophically poorly probably due to overly eagerly dispatch to dlatsqr which might be poorly optimised. OpenBLAS/IntelMKL performance may differ, I haven’t benchmarked dgeqr/dgemqr there.
Questions
- Should we adopt dgeqrt/dgemqrt in qr_multiply instead of dgeqrf/dormqr?
- What block size should we use
min(k,64)dgeqrf’s defaultnbor something else (I tried callingdgeqr’sILAENVto see if it gave a useful suggestion as implied by the LAPACK reference code but it just returned the fallback1). Note I triedmin(k,32)and the results weren’t overly different, slightly slower for large column sizes but not overly so. - How should we work towards supporting this in the new C++ framework, do we want it to support this immediately? Or should we start with direct calls to
scipy.lapack. If we useC++should we implement all ofqr_multiplyin one C++ function or one call fordgeqrtand one call fordgemqrt. Note the Python version is ~80 lines with lots of conditionals and branching so a pure C++ implementation wouldn’t be trivial (I feel confident I could do it with some effort but it may be hard to review).
Context:
I have recently implemented a JAX version of qr_multiply to build foundations for a faster least_squares (yes, we might be able to call gels or getsls directly for the forward pass but we need state exposure and LAPACK building blocks for the jvp rule) and I was rather disheartened about the performance on GPU in particular but also finding now that CPU could be a lot better. As, we try to stay fairly close to the reference scipy implementations in JAX I thought it would be worthwhile having the discussion about improving the qr_multiply implementation here first, not least because dgeqrt does not actually exist in cuSolver and we’d have to write a custom kernel or pure Jax method for it. On CPU with LAPACK>3.7 (scipy’s minimum) dgeqrt/dgemqrt is guaranteed to be available so the balance of considerations is simpler.