I have updated the scikit-sparse interface to CHOLMOD to be more similar to the scipy.linalg (dense) cholesky interface in my own development fork. I have a PR open to merge it.
I realize there are license issues with including SuiteSparse code directly in SciPy, but it seems like the interface to the headers and requiring SuiteSparse as a dependency is reasonable given the utility it would add to scipy.sparse.linalg. I am happy to work on incorporating this CHOLMOD interface into the scipy.sparse.linalg._dsolve module, as well as build the SPQR interface.
Similarly, I have also created interfaces to the AMD, COLAMD, etc. SuiteSparse matrix reordering routines that are available in my scikit-sparse development fork.
I am curious to hear everyone’s opinions on this topic. There is also certainly room for discussion around these items:
add license-compatible sparse Cholesky or incomplete Cholesky
add license-compatible sparse QR
although I would need someone with more expertise in licensing to weigh in on how to approach the algorithm design and implementation to avoid conflict with SuiteSparse itself.
Update: I’ve opened a draft PR #24101 with API updates to both the scikit-sparse CHOLMOD and newly-implemented scikit-sparse UMFPACK interfaces. We are still working on merging the v0.5.0 changes into scikit-sparse, but I will convert the draft once that is complete.
I have opened PRs in scikit-sparse for UMFPACK and SPQR interfaces.
Currently my development of scikit-sparse has the latest updates of these interfaces. I’ve completed some benchmarking to compare the v0.5.0 dev version with the existing v0.4.16 master branch.
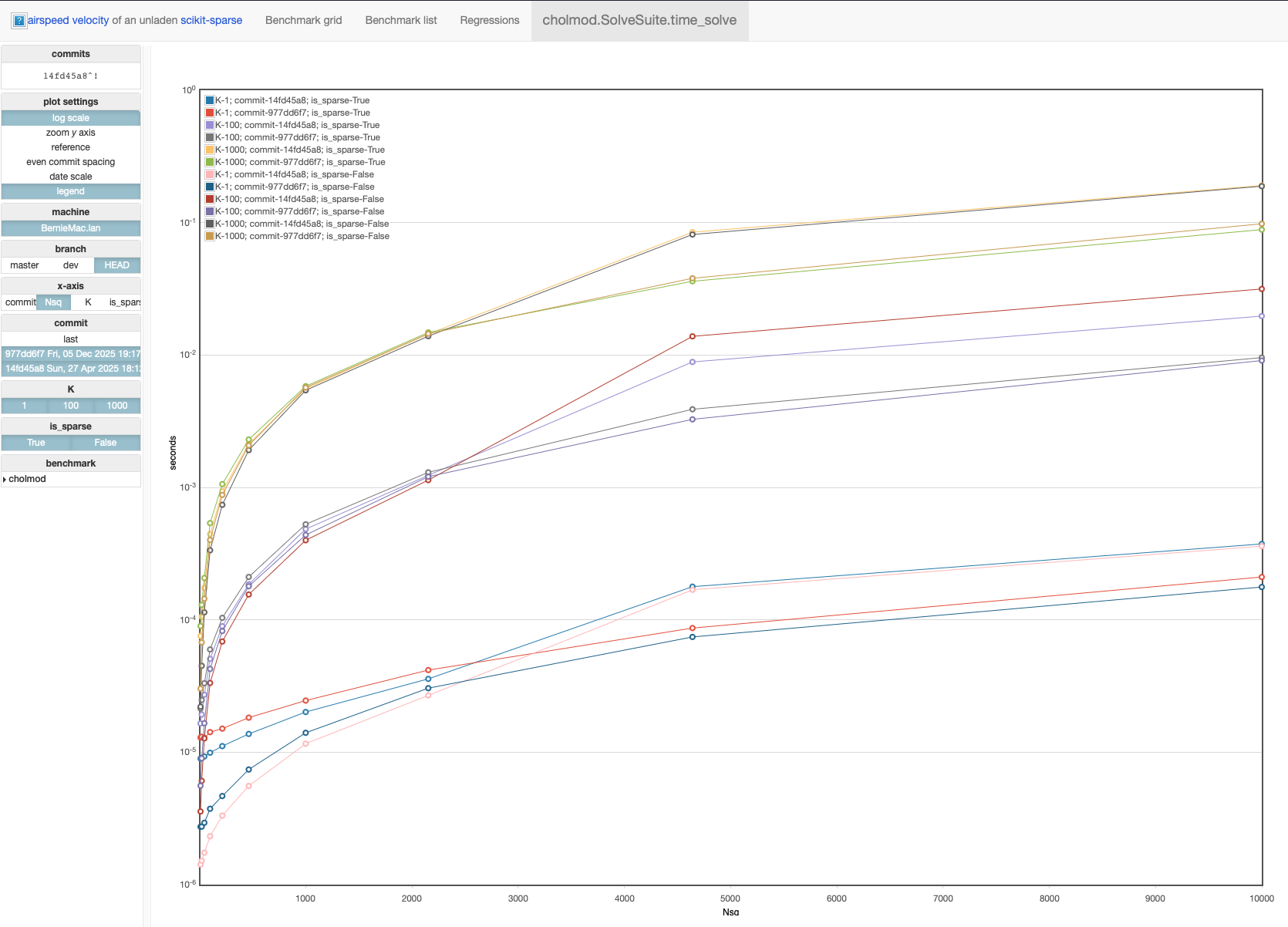
CHOLMOD benchmarks
The new CholeskyFactor.solve method (commit 977dd6f7) is a bit slower than the existing Factor.sovle_A (commit 14fd45a8) for smaller matrices, but substantially faster for large matrices:
I am not sure if the jump in runtime for larger matrices is a quirk of my machine or not.
See: the complete CHOLMOD asv benchmarks.
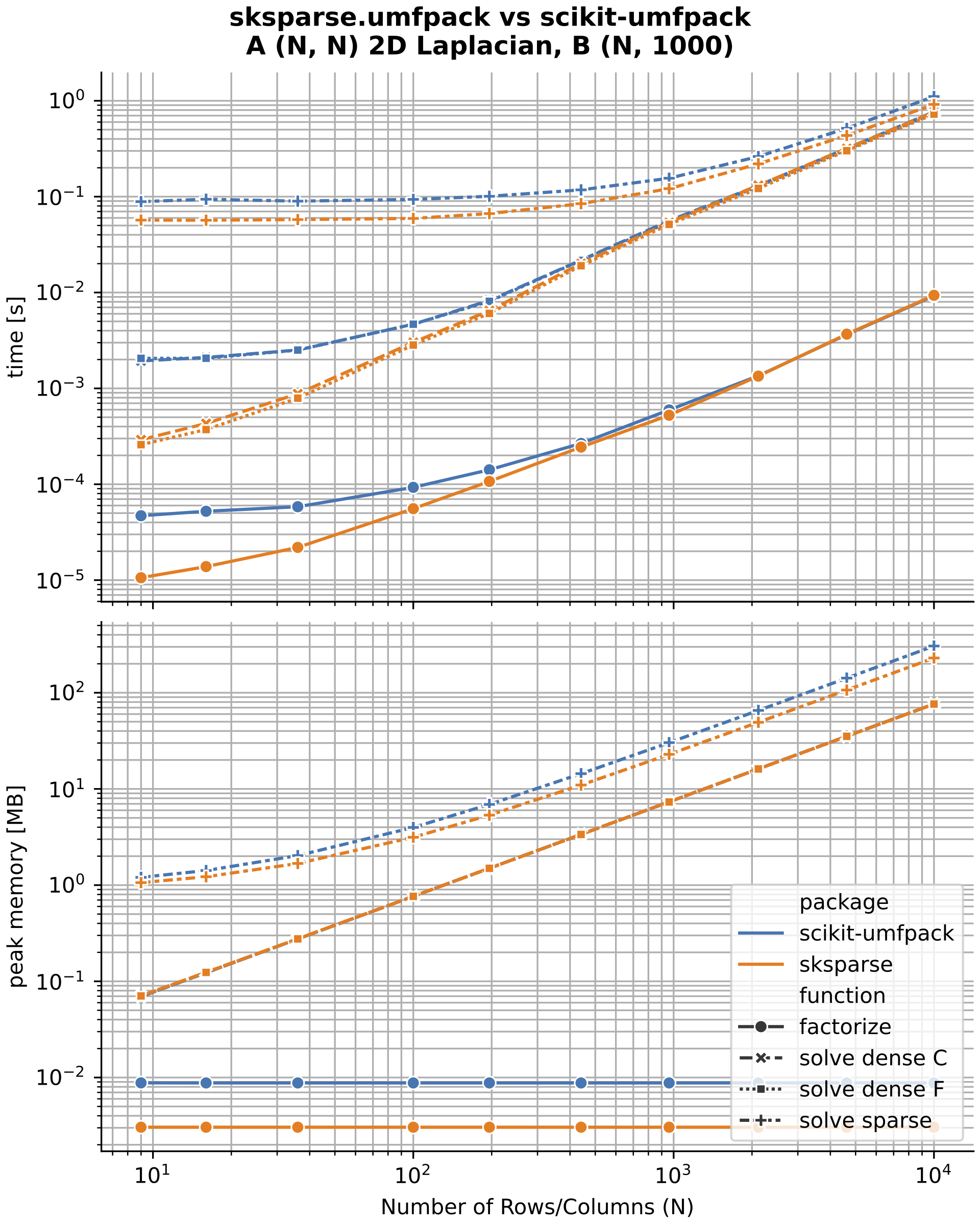
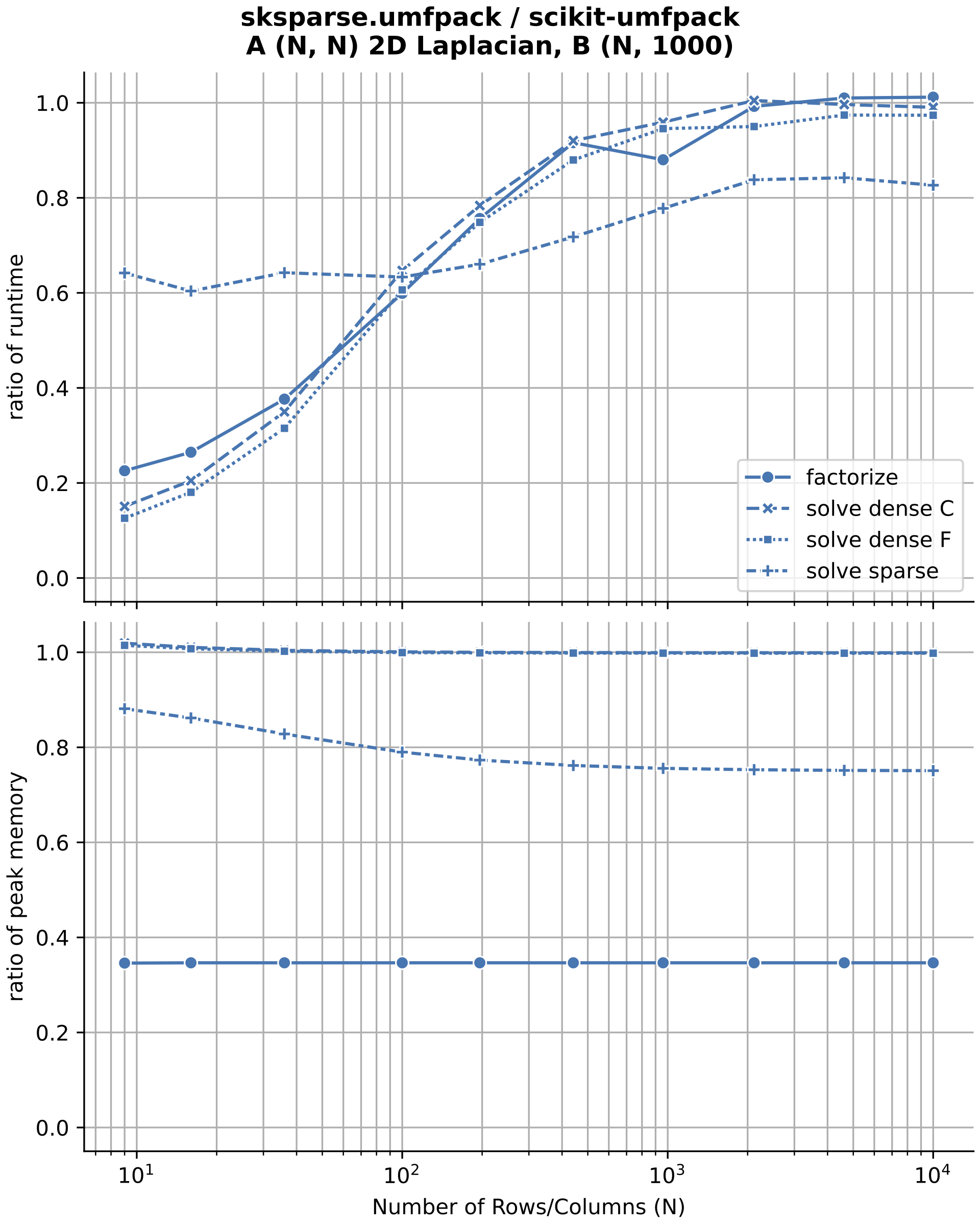
UMFPACK performance
I compared the new scikit-sparse UMFPACK interface (sksparse.umfpack) to the existing scikit-umfpack project. The existing project uses a SWIG interface that is slower and uses more memory than the scikit-sparse Cython interface.
Note that the timing ratio for all functions is expected to approach 1.0 as matrices get larger, since the underlying SuiteSparse UMFPACK functions dominate the computation time vs. the python wrapper.
Thanks for all your work here @broesler! The benchmark results look great.
The way you’ve done it in your open PR looks perfectly fine to me. We can’t actually take a direct dependency on either CHOLMOD (LGPL) or SPQR (GPL) for license reasons. So the try-except importing of scikit.sparse looks right.
That would have to be a fresh implementation without looking at the SuiteSparse implementation for reference.