I noticed a bug and some minor typos in the current signal.lombscargle function. It also has an unnecessary inner loop, which is why I assume the pyx version was created.
However, instead of filing a pull request to fix these issues, I’d rather just replace it with a more useful version, the generalized lomb-scargle periodogram (published a long while ago, but here is the arXiv link: [0901.2573] The generalised Lomb-Scargle periodogram. A new formalism for the floating-mean and Keplerian periodograms ). This version more correctly handles the cases where there is a y offset in the data, which just a naive removal of the mean will not fix. It also allows one to weight the individual sample points. I’ve already written and tested the function, including adding 2 additional output options (normalized power (which is common in some fields), and the complex representation (so one can make use of the phase information that is otherwise lost)).
The new code on my machine runs at ~1x the current compiled version (in scipy 1.13.1) for a sufficiently large input array and array of frequencies.
I wanted to solicit feedback on the best course of action.
In principle, if we keep the API the same, or only add keywords, it should be fine to replace. Or if your function improves functionality, we could also add the new function under a different name and deprecate the old one.
Those functions look very bespoke. Also, in the service of, I assume, working to mine everything out of the data, they’re doing things that I wouldn’t recommend for a general purpose tool (such as adjusting the frequency to find the exact peak). My understanding is that most of the functionality of scipy are generally common all-purpose tools that fit in specific categories of scientific analysis. So, I personally wouldn’t recommend that functionality.
As far as using them for examples of the Cython code, it isn’t really necessary. The vectorized numpy code, even with the extra calculations, is almost the same speed as the current compiled Cython implementation, and it would then remove two unnecessary files (_spectral.pyx and _spectral_.py, which both only contain the single, same, function). Although, I can easily transform my current numpy implementation to Cython, if desired.
The API is something I’ve thought about. Yes, there are at least 1 or 2 parameters that would have to be added. But there is currently 1 parameter, precenter that wouldn’t have to be removed, per se. But it would become functionally useless, since the generalized version always correctly handles any y offset (regardless of if the mean is removed ahead of time or not, the results will be -exactly- the same).
So, I could see fixing (or not) one of the parameter names (x → t), removing (or not) precenter, and then adding weights and complex (both with default values, so that existing code doesn’t break.
1=current, 2=desired, 3=only-additions:
def lombscargle(x, y, freqs, precenter=False, normalize=False):
def lombscargle(t, y, freqs, normalize=False, weights=None, complex=False):
def lombscargle(x, y, freqs, precenter=False, normalize=False, weights=None, complex=False):
If all numerical results change because the implementation is different and the optimal signature is different, then a new function seems nicer to me (and then the optimal signature can be used too). Unless it’s guaranteed that the new numerical results are always more accurate in a well-defined mathematical sense - but that is probably hard to guarantee with this type of algorithm.
If it’s almost as fast, a pure Python+NumPy implementation is much nicer.
In the case that there is no y offset, then the generalized version (GLS) mathematically reduces to the “original” lombscargle (LS). Now, numerically, is a different story (see final paragraph).
Although I’m not a fan of the default “power” units used for the current scipy lombscargle (since they bear no direct relation to the original signal amplitude, which is what most people would expect), I have my function output in the same units by default, so that it would still be a drop-in replacement. Therefore, 3 possible output options are:
default (same units for LS and GLS)
the peak value changes depending on power and the number of samples
normalized (same for LS and GLS)
the peak value reduces depending on the number of other peaks (and their relative powers), and noise
complex (new for GLS, where the amplitude is in the expected y units, with the phase also encoded–analogous to the FFT)
the peak value is always the amplitude of the sine wave at that given frequency, regardless of number of samples, other components, or noise
My code passes all of the current scipy LS tests (with a minor tweak in one of the tests to fix a numerical difference between LS/GLS). However, I feel like there should be additional tests, especially because the test suite misses a bug in the current LS code.
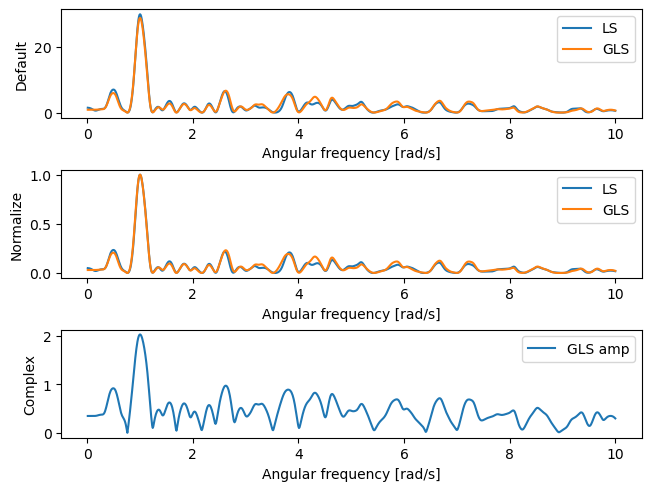
I just want to be clear, although mathematically the GLS and LS, reduce to the same formulas in the case that you assume the y offset is 0, given that the formulas are different (so that GLS can handle any y offset, including “clipped data” (always missing the peaks for instance)), numerically (with float64) the results will be ever so slightly different. I’ve included graphs using the current scipy LS test input data to compare the two. There is a single frequency and for that frequency’s power the results differ by 3.8% in the default units and 0% in the normalized. To @rgommers 's point about if “the new numerical results are always more accurate”, in this case, they are. The LS error is +6.3%, and the GLS error is +2.4% for the default units (normalized, both are perfectly accurate to within 1e-15).
I checked scipy for any examples of boolean arguments also permitting strings, and found that it seems to be allowed. So, I can simplify the API to just a new weights argument, while overloading the normalize with the ability to use False/True or “power” (False), “normalize” (True), “amplitude”. The precenter argument would still be non-functional.
(1 = current API, 2 = proposed)
def lombscargle(x, y, freqs, precenter=False, normalize=False):
def lombscargle(t, y, freqs, precenter=False, normalize=False, weights=None):
To reiterate, this would be a drop-in replacement for everyone that’s already using the current function, but would handle offset data more correctly, and allow the user to get amplitude+phase. Finally, it passes all current tests (with one minor tweak to one test)—but I’ll be adding more tests.
@stefanv or @rgommers (or anyone else looking), should I go ahead and start the PR to replace the current function?